InTDS ArchivebyCassie KozyrkovThe Obscure Art of Data DesignBattling an embarrassing new alchemy for the digital eraNov 22, 202216Nov 22, 202216
InTDS ArchivebyMadison SchottWhat is dbt?Your guide to analytics engineering and the tool that created itJul 13, 20215Jul 13, 20215
InThe Prefect BlogbyKhuyen TranOrchestrate Your Data Science Project with Prefect 2.0Make Your Data Science Pipeline Resilient Against FailuresJun 29, 20221Jun 29, 20221
InTinyclues VisionbyMike Aidane4 Design Principles for Robust Data PipelinesDesign Principals for traditional Software Engineering quickly fail when working with large and diverse sets of data — a new way of…Mar 11, 20222Mar 11, 20222
InDev GeniusbyAshish MJKafka with PythonThis article aims to outline the core concepts of Apache Kafka and write simple producer and consumer programs using python.Jan 23, 20222Jan 23, 20222
InTDS ArchivebyEmma RizziDeploying Prefect Server with AWS ECS and Docker StorageHow to orchestrate and automate workflows with Prefect running on ECS Fargate with a private Docker registryAug 24, 20211Aug 24, 20211
InDev GeniusbyHaq NawazPython ETL Pipeline: The Incremental data load TechniquesThe incremental data load approach in ETL (Extract, Transform and Load) is the ideal design pattern. In this process, we identify and…Mar 25, 20226Mar 25, 20226
Oladokun JosephA step-by-step guide to building a simple data pipeline with AirplaneThere are many layers to data engineering but the most important job of a data engineer is to build data pipelines that will make quality…Mar 27, 20221Mar 27, 20221
InBetter ProgrammingbySamhita Alla5 Open-Source Tools That Can Help You Build ML Pipelines With EaseAll production-friendlyFeb 11, 20221Feb 11, 20221
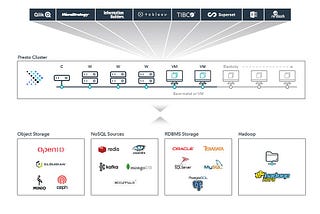
InSeattleDataGuy By SeattleDataGuybyBen RogojanStarburst Data Raised $100M — But What Is It?Looking At A Company Trying To Make Presto(now Trino, easier)Aug 28, 20211Aug 28, 20211
InITNEXTbyTobias WissmuellerEvent-Driven Architectures with Kafka and PythonEverything You Need to Get StartedOct 22, 20212Oct 22, 20212
InTDS ArchivebyJames BriggsSQL on The Cloud With PythonA straightforward guide to SQL on Google Cloud and PythonSep 4, 20207Sep 4, 20207
InElucidatabySahil RaiHow to Build Highly Effective ETL PipelinesA quick look at building inexpensive yet scalable ETL pipelinesFeb 21, 20224Feb 21, 20224
KestraIntroducing Kestra, infinitely scalable open source orchestration and scheduling platform.Today, our team is proud to announce a first public release of Kestra, an open-source platform to orchestrate & schedule any kinds of…Feb 2, 202211Feb 2, 202211
InGeek CulturebyMadison SchottAn Analytic Engineer’s Honest Review of AirbyteHow to ingest Mailchimp data into SnowflakeJan 14, 20222Jan 14, 20222
Anna GellerHow to Use Prefect and Monte Carlo to Achieve More Reliable Data PipelinesIntroducing Monte Carlo data lineage tasks in PrefectFeb 15, 20222Feb 15, 20222
InTDS ArchivebyKrasnov VitaliyBuilding Python Microservices with Apache Kafka: All Gain, No PainEngineers often use Apache Kafka in their everyday work. The major tasks that Kafka performs are: read messages, process messages, write…Nov 10, 20213Nov 10, 20213
Incisco-fpiebyMirko RacaGreat (data) expectations — automatic data quality validationWhen was the last time you spoke to your data?Feb 11, 20222Feb 11, 20222
InGeek CulturebyAndrea CapuanoAirflow for non-batch, non-scheduled workloadsOn December 2020 Apache released Airflow 2.0, introducing a lot of new interesting changes. The one that I find more appealing is the 17x…Jun 29, 2021Jun 29, 2021
Anna GellerHow to Make Your Data Pipelines More Dynamic Using Parameters in PrefectHow to pass runtime-specific parameter values to your data pipelinesJan 25, 2022Jan 25, 2022